Robot Arm
Reinforcement Learning
Created by Napat Sahapat
Western Sydney University
Robot Arm
Reinforcement Learning
Created by Napat Sahapat
Western Sydney University
Reinforcement Learning?
Reinforcement Learning?
State -> Agent -> Action
Reward
State <-> Action
Q(S,A)
State-Action Value
Soft Actor Critic
Soft Actor Critic
Critic finds the best Q function
Soft Actor Critic
Critic finds the best Q function
Actor evaluates current policy
Exploration is controlled by Temperature (Alpha) (Can be learned or fixed)
Architecture
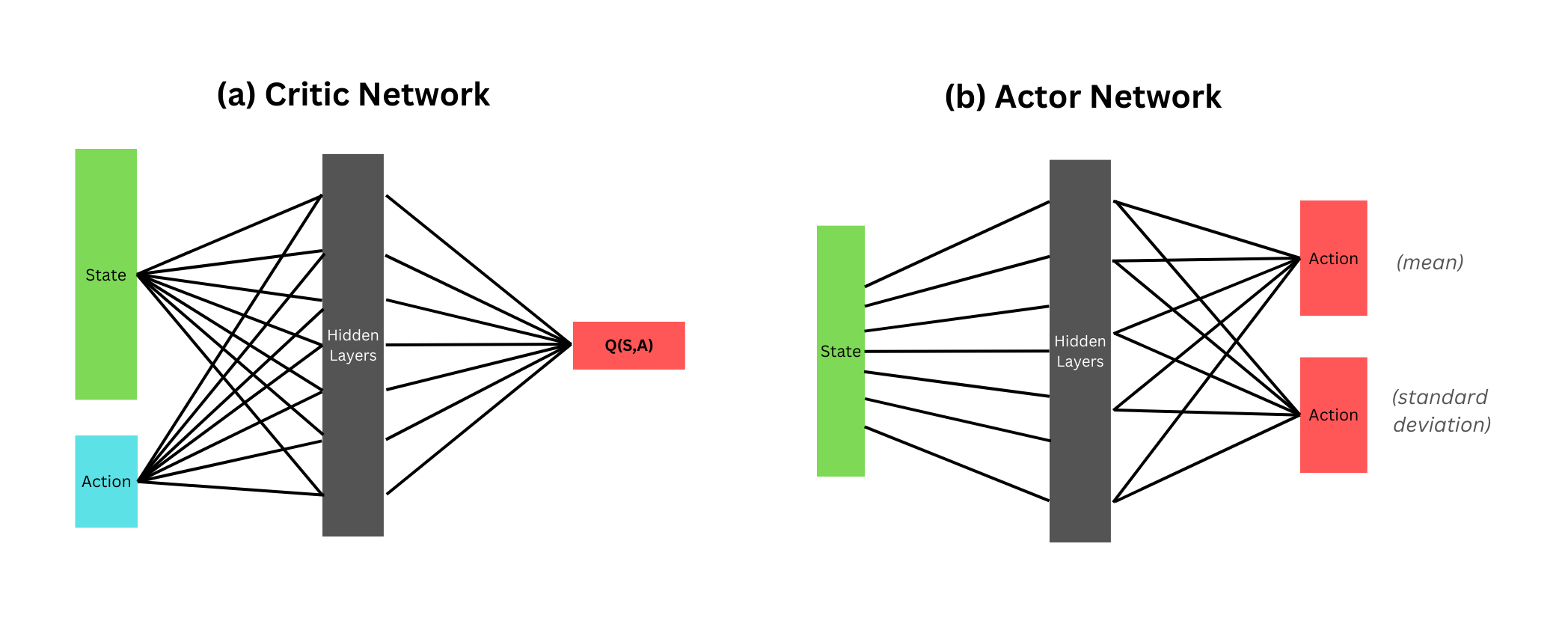
Actor
def actor_loss(self, states):
actions, log_prob, _ = self.get_action_prob(states)
q_values1 = self.critic1(torch.cat((states, actions), dim=1))
q_values2 = self.critic2(torch.cat((states, actions), dim=1))
min_q_values = torch.min(q_values1, q_values2)
policy_loss = (self.alpha * log_prob - min_q_values).mean()
return policy_loss, log_prob
Critic
def critic_loss(self, states, actions, rewards, nextstates, done):
with torch.no_grad():
next_actions, next_log_probs, _ = self.get_action_prob(nextstates)
next_q1 = self.target_critic1(torch.cat((nextstates, next_actions), dim=1))
next_q2 = self.target_critic2(torch.cat((nextstates, next_actions), dim=1))
min_next_q = torch.min(next_q1, next_q2)
soft_state = min_next_q - self.alpha * next_log_probs
target_q = rewards + (1 - done) * self.gamma * soft_state
pred_q1 = self.critic1(torch.cat((states, actions), dim=1))
pred_q2 = self.critic2(torch.cat((states, actions), dim=1))
loss1 = self.criterion(pred_q1, target_q)
loss2 = self.criterion(pred_q2, target_q)
return loss1, loss2
Alpha (Temperature)
def temperature_loss(self, log_prob):
loss = -(self.log_alpha * (log_prob + self.target_entropy).detach()).mean()
return loss
Discrete Actions
Continuous SAC
Multi-Discrete SAC
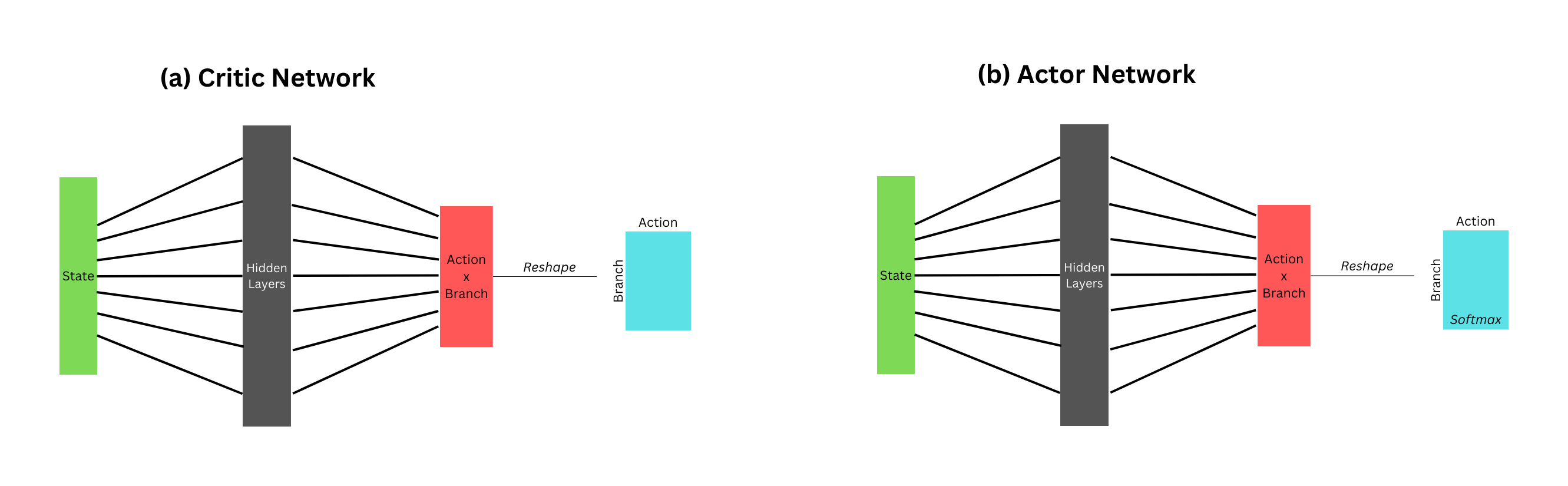
Environment Setup
Environment Setup
Environment Setup
Observation (10)
- Joint Rotations (7)
- Target Position (x,y,z)
Discrete Actions (3)
- Left (0)
- Stationary (1)
- Right (2)
Reward
- + Hit Target (Reset)
- + Get Closer to Target
- - Collide with Table
- - Body Hits Target
First Attempt
First Attempt
Result is very embarrassing...
Let's try with simpler environments...
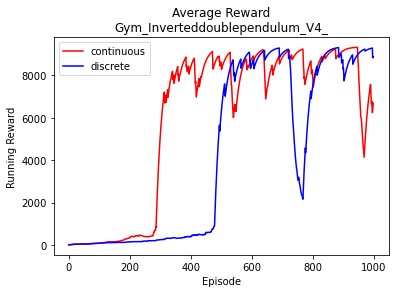
Inverted Double Pendulum
- 11 Observations
- 1 Continuous Actions
Inverted Double Pendulum
Continuous SAC
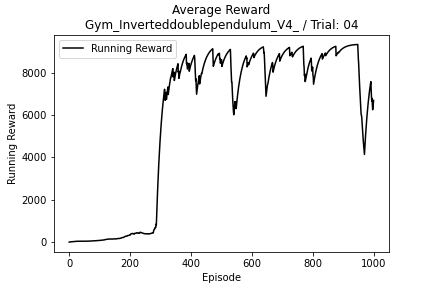
Inverted Double Pendulum
Discrete SAC
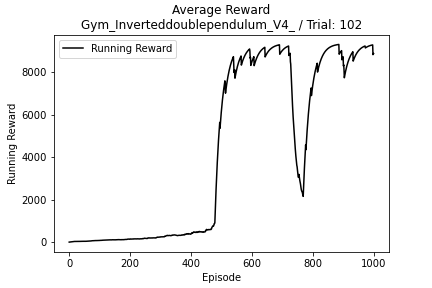
Inverted Double Pendulum
Comparison
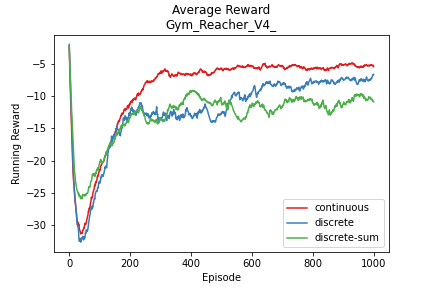
Reacher
- 11 Observations
- 2 Continuous Actions
Reacher
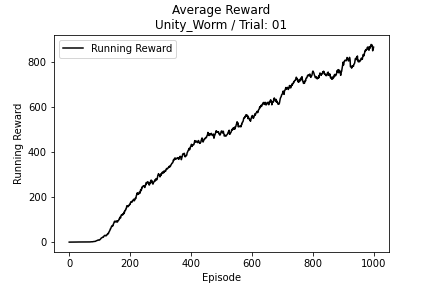
Worm (Unity)
Goal:
Wiggle to target as quickly as possible
- 64 Observations
- 9 Continuous Actions
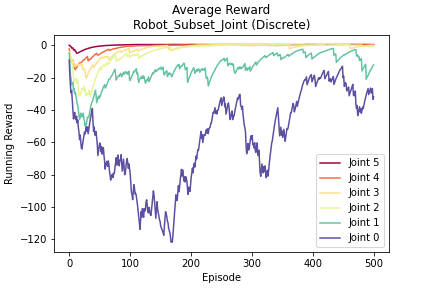
Joint Subset
Joint Subset
Split joints into manageable chunks
Joint Subset
Joint 5
Joint Subset
Joint 5
Joint 4
Joint Subset
Joint 5
Joint 4
Joint 3
Joint Subset
Joint 5
Joint 4
Joint 3
Joint 2
Joint Subset
Joint 5
Joint 4
Joint 3
Joint 2
Joint 1
Joint Subset
Joint 5
Joint 4
Joint 3
Joint 2
Joint 1
Joint 0
Joint Subset
Comparison
Lessons
Lessons
Learning Rate vs EntropyEarly exploration is very important
Improvements
Improvements
Slowly unfreezing joints (Incremental Learning)
Improvements
Slowly unfreezing joints (Incremental Learning)
Reward Shaping